
1. Relational Languages
Edgar Codd 在 1970 年代早期发表了关系模型的经典论文。 最初他只定义了数学上的表示方法,描述 DBMS 如何在关系模型上执行查询。 用户只需要用声明式语言(也就是 SQL)告诉系统「我想要什么结果」, 而由 DBMS 自己负责找出最高效的执行计划来产生答案。
关系代数基于集合(set):无序、不允许重复元素。 SQL基于包/多重集(bag):无序、允许重复行。
2. SQL History
SQL 是关系数据库的声明式查询语言。 它诞生于 1970 年代,是 IBM System R 项目的一部分。 最初被命名为 SEQUEL(Structured English Query Language,结构化英语查询语言)。 由于商标冲突,1980 年代改名为 SQL(Structured Query Language,结构化查询语言)。
SQL 包含几大类命令:
- DML(数据操纵语言):SELECT、INSERT、UPDATE、DELETE
- DDL(数据定义语言):定义表、索引、视图等模式
- DCL(数据控制语言):权限与访问控制
SQL 远未过时,每隔几年都会增加新特性。 要声称「支持 SQL」,至少要实现 SQL-92 标准。 不过各个数据库厂商在遵循标准的同时,都加入了很多自己的专有扩展。
SQL 标准的主要更新节点包括:
- SQL:1999:正则表达式、触发器
- SQL:2003:XML 支持、窗口函数、序列
- SQL:2008:表截断(TRUNCATE)、更强大的排序功能
- SQL:2011:时态数据库、流水线 DML
- SQL:2016:JSON 支持、多态表
- SQL:2023 属性图查询,多维数组
这是我们在之后的所有例子中用到的数据库样式。
CREATE TABLE student (
sid INT PRIMARY KEY,
name VARCHAR(16),
login VARCHAR(32) UNIQUE,
age SMALLINT,
gpa FLOAT
);
CREATE TABLE course (
cid VARCHAR(32) PRIMARY KEY,
name VARCHAR(32) NOT NULL
);
CREATE TABLE enrolled (
sid INT REFERENCES student(sid),
cid VARCHAR(32) REFERENCES course(cid),
grade CHAR(1)
);
3. Joins
连接(Join)将一个或多个表中的列组合起来,生成一个新的表。用于表达那些数据跨越多个表的查询。 Example:Which students got an A in 15-721?
SELECT s.name
FROM enrolled AS e, student AS s
WHERE e.grade = 'A'
AND e.cid = '15-721'
AND e.sid = s.sid;
-- 这是Spring 2023版本
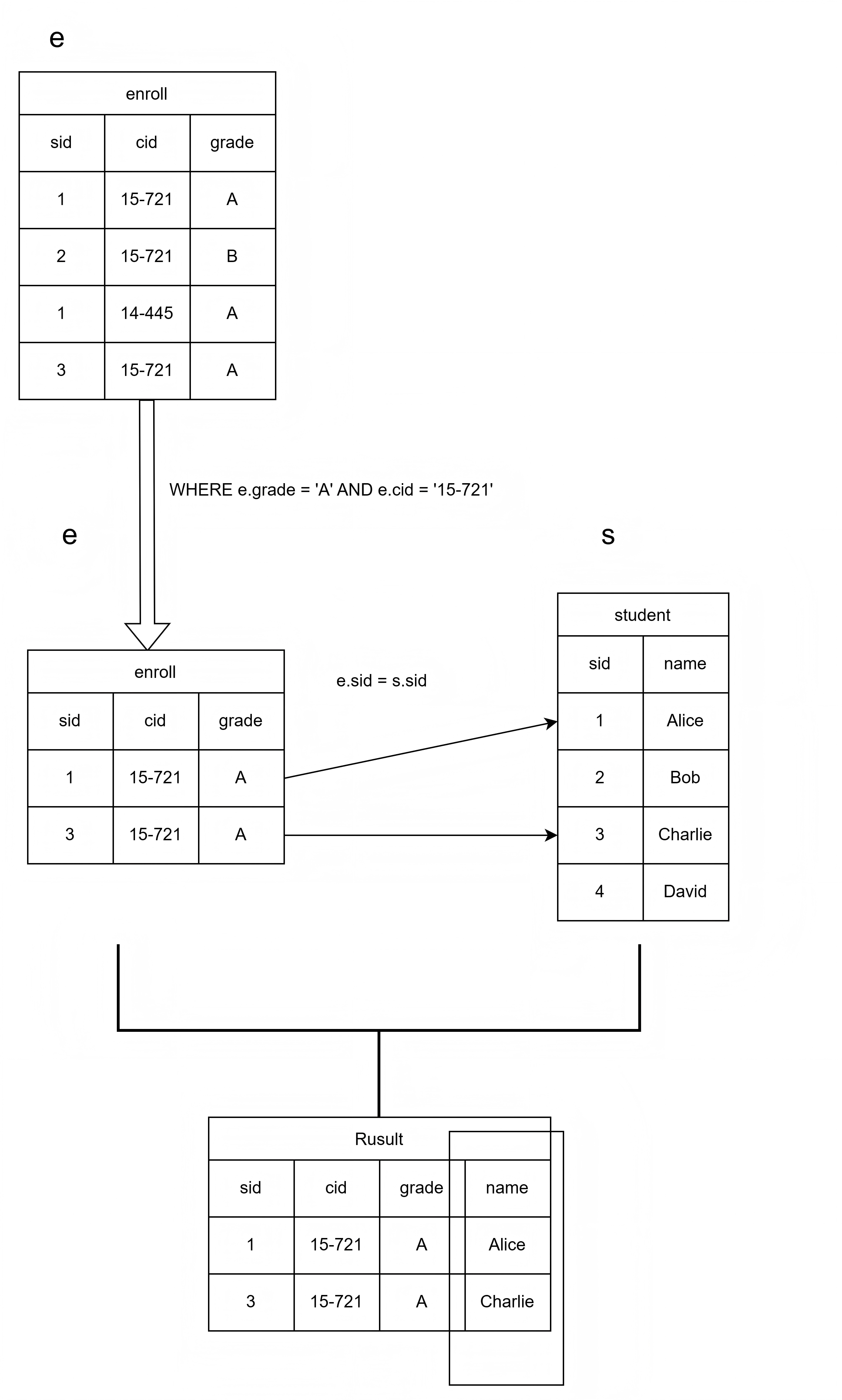 这里我要解释一下,因为在严格按照讲义中所说的做,应该是先做笛卡尔积,生成一张巨大的临时表,然后再根据 WHERE 条件来筛选。但是依照Lecture Notes - 01的Observation中所说。SQL实际上会执行效率最高的行为来达到我们想要的效果。因此现在这种形式更接近于SQL内部做的操作。
注:
这里我要解释一下,因为在严格按照讲义中所说的做,应该是先做笛卡尔积,生成一张巨大的临时表,然后再根据 WHERE 条件来筛选。但是依照Lecture Notes - 01的Observation中所说。SQL实际上会执行效率最高的行为来达到我们想要的效果。因此现在这种形式更接近于SQL内部做的操作。
注:
SELECT s.name
FROM enrolled AS e
JOIN student AS s ON e.sid = s.sid
WHERE e.grade = 'A' AND e.cid = '15-721';
-- 这是现代推荐的写法。后续也会遇到,因此解释一下。
语法:
JOIN:用于联合两张表,仅返回两张表中满足连接条件的匹配行。ON:是JOIN的专属子句,用于定义两张表进行匹配的关联条件。
4. Aggregates
一个聚合(Aggregates)函数将一个元组的包(bag)作为其输入,然后产生一个单一的标量值作为其输出。 使用限制:几乎只能出现在 SELECT 输出列表中。
- AVG(COL) : The average of the values in COL
- MIN(COL) : The minimum value in COL
- MAX(COL) : The maximum value in COL
- SUM(COL) : The sum of the values in COL
- COUNT(COL) : The number of tuples in the relation
Example: Get # of students with a ‘@cs’ login. 以下三种写法等价:
SELECT COUNT(*) FROM student WHERE login LIKE '%@cs';
SELECT COUNT(login) FROM student WHERE login LIKE '%@cs';
SELECT COUNT(1) FROM student WHERE login LIKE '%@cs';
Why are they equivalent?
因为对于student,系统会先执行FROM...WHERE...,之后留下的行数就是在login列保留@cs的行,因此以下三者等价:
- count(*):统计所有行数。
- count(login):统计login列值非NULL的行数。
- count(1):SQL 会为满足 WHERE 条件的每一行都生成一个 1,count(1)则是统计共有几个1的语句。
事实上,并非所有情况下,这三者均等价,但是在这个situation中,三者均统计满足 WHERE login LIKE '%@cs' 条件的行数.
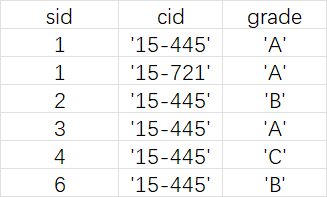
为了更好理解,我创建了一个数据库,并依此来展示不同的语句出现的不同效果: 下列两张图片分别为 student 和 enrolled:

部分聚合函数 (e.g. COUNT, SUM, AVG) 支持 DISTINCT(去重后聚合): Example: Get # of unique students and their average GPA with a ‘@cs’ login.
SELECT COUNT(DISTINCT login) FROM student WHERE login LIKE '%@cs';
单个SELECT语句可以包含多个聚合函数: Example: Get # of students and their average GPA with a ‘@cs’ login.
SELECT AVG(gpa), COUNT(sid) FROM student WHERE login LIKE '%@cs';

重要规则 1:没有 GROUP BY 时,不能混用聚合列和其他普通列(否则结果未定义!) Example: Get the average GPA of students in each course.
SELECT AVG(s.gpa), e.cid FROM enrolled AS e JOIN student AS s ON e.sid = s.sid;
-- e.cid 值未定义!
SQL:2023 新特性:ANY_VALUE(e.cid)(允许取任意值) Example: Get the average GPA of students in each course.
SELECT AVG(s.gpa), ANY_VALUE(e.cid) FROM enrolled AS e JOIN student AS s ON e.sid = s.sid;
-- ANY_VALUE(e.cid)就是从e.cid这一列中任取一个值

重要规则 2:GROUP BY + 非聚合列
必须把非聚合列写进 GROUP BY:
Example: Get the average GPA of students in each course.
SELECT AVG(s.gpa), e.cid
FROM enrolled e JOIN student s ON e.sid = s.sid
GROUP BY e.cid;

HAVING 子句(分组后过滤,相当于 GROUP BY 的 WHERE): Example: Get the set of courses in which the average student GPA is greater than 3.9.
SELECT AVG(s.gpa) AS avg_gpa, e.cid
FROM enrolled e, student s
WHERE e.sid = s.sid
GROUP BY e.cid
HAVING AVG(s.gpa) > 3.9; -- 注意标准写法要重复 AVG

5. String Operations
字符串基本规则(SQL 标准): • 区分大小写(case-sensitive):‘Alice’ ≠ ‘alice’。 • 只能用单引号(single quotes):‘hello’(双引号在某些系统如 MySQL 可用于标识符或字符串,但标准只认单引号)。 模式匹配(LIKE):
- %:匹配任意长度子串(包括 0 长度)。
- _:匹配正好 1 个字符。 Example:
SELECT * FROM student WHERE login LIKE '%@cs'; -- 所有 cs 域邮箱
SELECT * FROM student WHERE name LIKE 'A___e'; -- A 开头、5 个字符、以 e 结尾(如 Alice)
SELECT * FROM course WHERE cid LIKE '15-%'; -- 所有 15 开头的课程
标准字符串函数:
- SUBSTRING(S, B, E):从字符串的第个位置开始,截取长度为的子串。
- UPPER(S):转大写。 字符串拼接:
- ||(SQL 标准符号)
SELECT name || '@cs.cmu.edu' AS email FROM student;
6. Date and Time
数据库通常需要跟踪日期和时间,因此 SQL 支持对 DATE 和 TIME 属性进行操作。这些操作既可以用作输出,也可以用作谓词(Predicate)。 P.S. Predicate 的意思其实可以理解为「筛选条件」。例如:
SELECT * FROM course WHERE cid LIKE '15-%';
其中cid LIKE '15-%'就是 Predicate。
不同系统中日期和时间操作的具体语法可能会有很大差异。
7. Output Redirection
除了让一个查询 (query) 返回的结果发送给客户端 (client)(e.g. terminal),我们也可以让 DBMS 将结果存储到另一个表 (table) 中。以便我们在后续 query 中可以访问这些数据。
- New Table:将查询的输出存储到一个新的(永久性)的表中。
For Example: 从
enrolled表中提取不重复的课程 ID 并存入新表CourseIds。
SELECT DISTICT cid INTO CourseIds FROM enrolled;
- Existing Table:将查询的输出存储到一个已经存在于数据库的表中。目标表 (target table) 必须拥有与结果集相同数量的 columns 以及相同的 types,但输出查询 (output query) 中的列名不需要匹配。
For Example:将提取的结果插入已存在的
CourseIds表。
INSERT INTO CourseIds (SELECT DISTINCT cid FROM enrolled)
8. Output Control
因为SQL的查询结果是无序的,所以我们必须使用ORDER BY clause来对tuples进行排序。
SELECT sid,grade FROM enrolled WHERE cid = '15-721'
ORDER BY grade;
默认的排序顺序是 升序 (ASC)。我们可以手动指定 降序 (DESC) 来反转顺序。
SELECT sid,grade FROM enrolled WHERE cid = '15-721'
ORDER BY grade DESC;
我们可以使用多个 ORDER BY 子句 (ORDER BY clauses) 来处理平局 (ties) 或进行更复杂的排序。
SELECT sid,grade FROM enrolled WHERE cid = '15-721'
ORDER BY grade DESC,sid ASC;
我们还可以在 ORDER BY clause 中使用任何任意表达式 (arbitrary expression)。
SELECT sid FROM enrolled WHERE cid = '15-721'
ORDER BY UPPER(grade) DESC, sid + 1 ASC;
默认情况下,DBMS 会返回查询产生的所有 tuples。我们可以使用 LIMIT clause 来限制结果 tuples 的数量。
SELECT sid,name FROM student WHERE login LIKE '%@cs'
LIMIT 10;
我们还可以提供一个 偏移量 (offset) 来返回结果中的一个范围。
SELECT sid,name FROM student WHERE login LIKE '%@cs'
LIMIT 20 OFFSET 10; -- 跳过前10行,从第11行读到第20行
除非我们在使用 LIMIT 的同时使用 ORDER BY clause,否则 DBMS 在每次执行查询时可能会产生不同的 tuples 结果,因为 Relational Model 本身并不强制要求排序。
9. Windows Functions
窗口函数(Window Functions)在一组相关的元组上执行「滑动」计算(sliding calculation),类似于aggregation,但不会把多行塌缩成一行(tuples are not collapsed into a single output tuple)。
每一行都会保留原样,同时在旁边多出一列计算结果。
The difference bettwen Aggregation and Windows Functions:
- Aggregation:多行变成一行(collapse)。
- Windows Functions:多行变成多行加计算值。 概念执行(conceptual execution): 讲义给出的想象步骤:
- 表被分区(partitioned)
- 每个分区内部按 ORDER BY 排序(sorted)
- 对每一条记录,创建一个跨越多条记录的窗口(window spanning multiple records)
- 为每个窗口计算输出值。 常用窗口函数(Window Functions)
- 普通聚合函数也可以当窗口函数用: AVG()、SUM()、COUNT()、MIN()、MAX() 等 (在 OVER 子句中使用时,就变成窗口版本)
- 专用窗口函数(Special Window Functions):
- ROW_NUMBER():当前行的序号(从 1 开始,唯一且连续)
- RANK():当前行的排名(有并列时跳号,例如 1,1,3)
- DENSE_RANK()(讲义未提,但常见):并列不跳号(1,1,2) OVER Clause—— 分组与排序的核心 OVER 子句决定如何把元组分组和排序。
- PARTITION BY:指定分组依据(类似 GROUP BY,但不塌缩行)
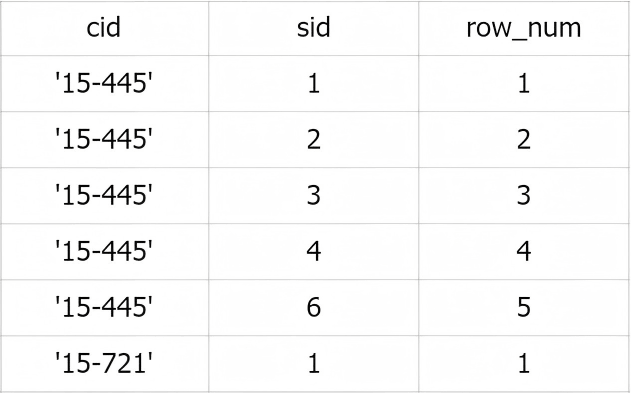
- ORDER BY:在每个分区内部的排序顺序(决定 ROW_NUMBER、RANK 的计算顺序) Exmple1:为每门课(cid)内的选课记录编号:
SELECT
cid,
sid,
ROW_NUMBER() OVER (PARTITION BY cid) AS row_num
FROM enrolled
ORDER BY cid;
Result:每门课从 1 开始重新编号。
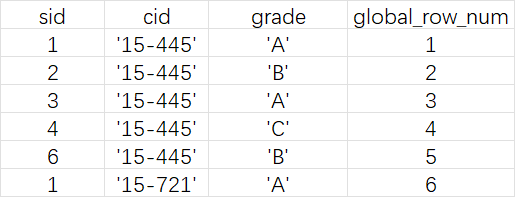
Example2:全局编号(不分区,只排序)
SELECT
*,
ROW_NUMBER() OVER (ORDER BY cid) AS global_row_num
FROM enrolled
ORDER BY cid;
IMPORTANT difference
- ROW_NUMBER():在排序之前分配序号(deterministic,即使内部排序变化也稳定)
- RANK():在窗口函数的 ORDER BY 排序之后计算排名(可能因并列而跳号)
讲义示例(注意 ORDER BY grade ASC,因为成绩是 ‘A’,‘B’,‘C’ 而非数字):
SELECT *
FROM (
SELECT
*,
RANK() OVER (
PARTITION BY cid
ORDER BY grade ASC -- A < B < C,所以 ASC 让 A 排第一
) AS rank
FROM enrolled
) AS ranking
WHERE ranking.rank = 2;
10. Nested Question
嵌套查询(Nested Queries)是指在一个查询内部嵌套另一个查询,用于在单个 SQL 语句中实现更复杂的逻辑。 嵌套查询也常被称为子查询(Subqueries)。 重要特点:
- 嵌套查询通常难以优化(difficult to optimize),性能可能较差。
- 外层查询(outer query)的范围(scope)可以被内层查询访问(inner query can access attributes from outer query),但反过来不行(the opposite is not true)。
子查询可以出现在查询的几乎任何位置:
- SELECT 输出列表(SELECT Output Targets)
- FROM 子句(FROM Clause)
- WHERE 子句(WHERE Clause)
Example: Get the names of students that are enrolled in ‘15-445’.
SELECT name FROM student
WHERE sid IN (
SELECT sid FROM enrolled
WHERE cid = '15-445'
);
Note
同一个列名(如 sid)在不同查询层中作用域(scope)不同。内层查询的 sid 和外层查询的 sid 可能指向不同表。
Example: Find student record with the highest id that is enrolled in at least one course.
SELECT student.sid, name
FROM student
JOIN (
SELECT MAX(sid) AS sid
FROM enrolled
) AS max_e
ON student.sid = max_e.sid;
10.1 Nested Query Results Expressions
子查询返回结果后,外层常用以下方式处理:
- ALL:必须满足子查询中所有行的条件
- ANY:只要满足子查询中至少一行的条件即可
- IN:等价于 = ANY()(最常用)
- EXISTS:只要子查询返回至少一行就为真(常用于相关子查询)
Example: Find all courses that have no student enrolled in it.
SELECT *
FROM course
WHERE NOT EXISTS (
SELECT *
FROM enrolled
WHERE course.cid = enrolled.cid
);
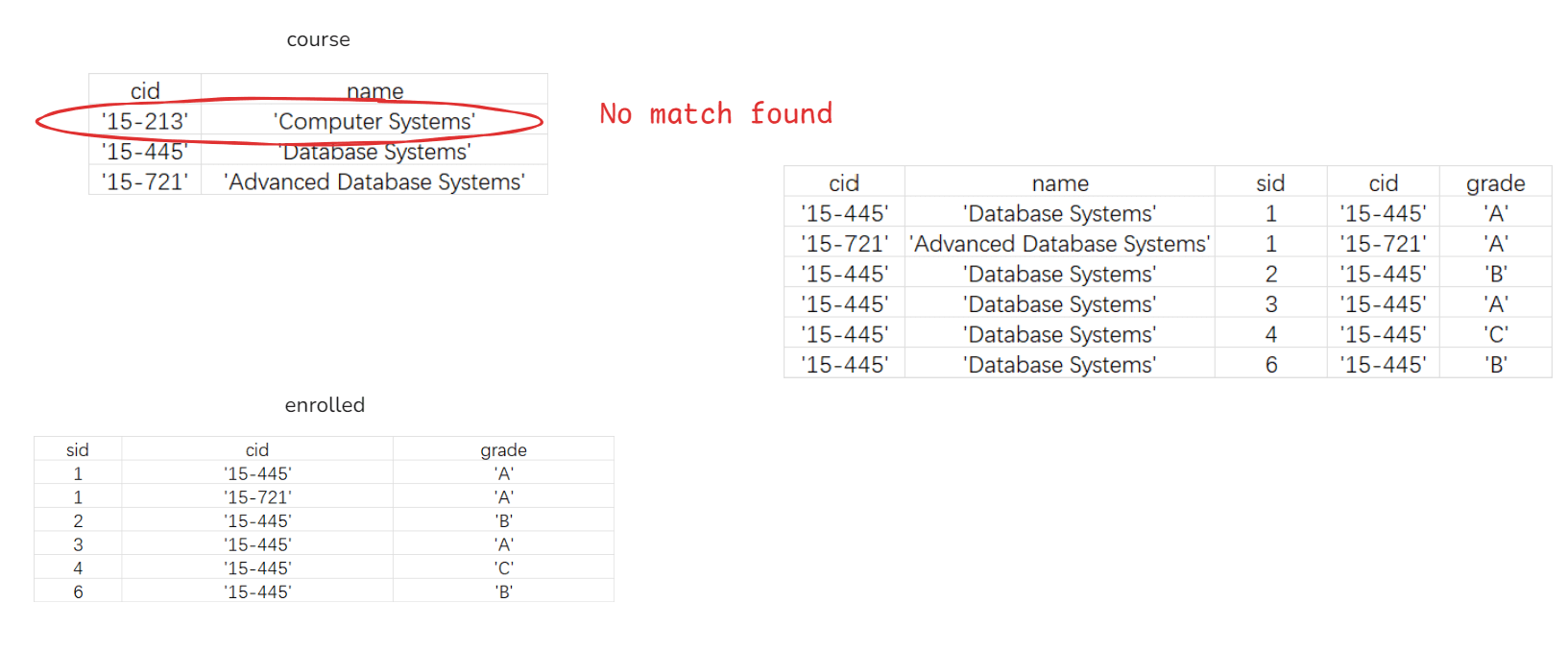
11. Lateral Joins
LATERAL 是 SQL 中一个非常强大的操作符,它允许嵌套查询(subquery)引用前面出现的表或子查询中的列。 你可以把 LATERAL Join 想象成一个 for 循环:
- 对外层表(这里是 course)的每一行(each tuple),都去执行一次内层的子查询。
- 内层子查询可以直接访问外层当前行的属性(例如 c.cid)。 Example: 计算每门课程(course)的选课人数(enrollment count)和选课学生的平均 GPA,并按选课人数降序排序。
SELECT *
FROM course AS c
LATERAL (
SELECT COUNT(*) AS cnt
FROM enrolled
WHERE enrolled.cid = c.cid -- 可以直接引用外层的 c.cid
) AS t1,
LATERAL (
SELECT AVG(s.gpa) AS avg
FROM student AS s
JOIN enrolled AS e ON s.sid = e.sid
WHERE e.cid = c.cid -- 同样可以引用 c.cid
) AS t2;
12. Common Table Expressions
Common Table Expressions (CTEs) 是编写复杂查询时的一种强大工具,它作为嵌套查询(Nested Queries和窗口函数(Window Functions)的替代方案出现。 CTE 可以看作是只在当前查询中有效的临时表(temporary table scoped to a single query)。 WITH 子句的作用:把内层查询的结果绑定到一个临时表名上,后续可以像普通表一样引用它。 Example1:Simplest CTE
WITH cteName AS (
SELECT 1
)
SELECT * FROM cteName;

Example2:为CTE的输出列指定名称。
WITH cteName (col1, col2) AS (
SELECT 1, 2
)
SELECT col1 + col2 FROM cteName;
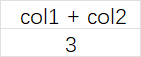
Example3:一个查询中包含多个CTE
WITH cte1 (col1) AS (SELECT 1),
cte2 (col2) AS (SELECT 2)
SELECT * FROM cte1, cte2;

12.1 Advanced Features
在 WITH 后面加上 RECURSIVE 关键字,CTE 就可以引用自己,从而实现递归(recursion)。 这使得 SQL 具备了图灵完备(Turing-complete)的计算能力(虽然写起来比较繁琐)。 Example:Print the sequnence of numbers from 1 to 10.
WITH RECURSIVE cteSource (counter) AS (
(SELECT 1) -- 初始种子(anchor member)
UNION
(SELECT counter + 1 -- 递归部分(recursive member)
FROM cteSource
WHERE counter < 10)
)
SELECT * FROM cteSource;